Introduction
Machine learning is an exciting field, but it comes with its challenges. One of the most important concepts every practitioner must understand is the bias variance tradeoff. It might sound complex at first, but once you break it down, it’s easier than it seems. Simply put, this concept helps us understand why our models sometimes perform well on training data but poorly on new data. It’s all about finding the right balance between underfitting and overfitting, ensuring that our predictions are accurate and reliable.
Imagine you’re trying to hit a target with a bow and arrow. If all your arrows land far from the target, that’s like high bias. If your arrows are scattered all over, that’s like high variance. The trick is to find the sweet spot where your arrows consistently hit near the bullseye. That’s exactly what machine learning models aim to do: minimize both bias and variance to improve accuracy.
What is Bias in Machine Learning?
Bias is the error introduced by approximating a real-world problem with a simplified model. In simple terms, it’s when a model is too rigid and fails to capture the true patterns in the data. High bias leads to underfitting, meaning your model doesn’t learn enough from the data.
For example, imagine trying to predict house prices with only the size of the house, ignoring location, age, or amenities. Your model is too simple and won’t make accurate predictions. High bias models are consistent but wrong. They make systematic errors that cannot be fixed just by adding more data.
Understanding bias is crucial because it directly impacts a model’s ability to generalize. If the bias is too high, no matter how much you train your model, it will never perform well on real-world data. Recognizing bias early can save time and improve model design.
What is Variance in Machine Learning?
Variance, on the other hand, is when a model is too sensitive to small changes in the training data. High variance leads to overfitting, meaning your model performs exceptionally on training data but poorly on unseen data.
Think of a student who memorizes all the answers from last year’s test. They excel at repeating those questions but fail when faced with new problems. Similarly, high variance models capture noise and irrelevant details in the data.
While variance allows a model to be flexible, too much of it harms its ability to generalize. Balancing variance with bias is the key to building robust models that perform well across different datasets.



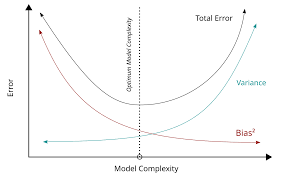
The Bias Variance Tradeoff Explained
The bias variance tradeoff is the balance between two sources of error in your model: bias and variance. Reducing one often increases the other, so the challenge is to find an optimal balance.
A simple analogy is adjusting the zoom on a camera. Too much zoom (high variance) captures unnecessary details, while too little zoom (high bias) misses important features. The goal is to find the perfect zoom level to get a clear picture.
In machine learning, this means choosing the right model complexity. Too simple, and you underfit; too complex, and you overfit. Mastering this tradeoff is essential for building models that are both accurate and generalizable.
How Underfitting Affects Model Performance
Underfitting happens when a model is too simple to capture the underlying patterns in the data. It’s often caused by high bias.
For example, predicting stock prices using only the day of the week would result in underfitting. The model ignores critical factors like market trends, news, and economic indicators. Underfitting leads to poor performance on both training and test data, making the model unreliable.
Addressing underfitting usually involves increasing model complexity, adding relevant features, or using more sophisticated algorithms. Recognizing underfitting early helps prevent wasted time and effort in model training.
How Overfitting Impacts Model Accuracy
Overfitting occurs when a model learns not only the true patterns but also the noise in the training data. This is often caused by high variance.
For instance, a decision tree that memorizes every training example will excel in training but fail on new data. Overfitting gives a false sense of model accuracy and can lead to poor decision-making in real-world applications.
To combat overfitting, techniques like regularization, pruning, cross-validation, and adding more training data are commonly used. The goal is to create a model that performs well on both seen and unseen data.
Real-Life Example of Bias Variance Tradeoff
Consider predicting whether a patient has diabetes. A simple model using just age and weight may be biased, underfitting the problem. A highly complex model with dozens of features, including irrelevant ones, may overfit.
The ideal model captures enough relevant factors without being distracted by noise. This balance ensures that predictions are accurate for both current patients and new patients in the future.
Real-life applications like this highlight why understanding the bias variance tradeoff is critical for professionals in healthcare, finance, and other industries.
Techniques to Manage Bias
Managing bias involves making your model more flexible and capable of capturing real patterns in the data. Common strategies include:
- Using more features that are relevant to the problem.
- Selecting more sophisticated algorithms like ensemble methods.
- Reducing assumptions about data relationships.
It’s essential to carefully add complexity without swinging too far toward overfitting. Testing different approaches with validation datasets can help identify the right balance.
Techniques to Manage Variance
Managing variance involves controlling overfitting and making the model generalize better. Effective strategies include:
- Regularization techniques like Lasso or Ridge.
- Using simpler models when possible.
- Increasing training data to reduce sensitivity to noise.
Cross-validation is a powerful tool to test whether a model generalizes well. Combining these techniques ensures your model avoids memorizing noise and focuses on meaningful patterns.
Cross-Validation and the Tradeoff
Cross-validation is a method to assess how a model will perform on unseen data. It’s essential for balancing bias and variance.
By dividing your dataset into multiple folds and training/testing iteratively, cross-validation provides a reliable estimate of model performance. It helps detect overfitting and underfitting early, guiding adjustments to model complexity or feature selection.
Without cross-validation, you risk building models that perform well only on training data, missing the mark on real-world applications.
Role of Ensemble Methods
Ensemble methods like Random Forests or Gradient Boosting combine multiple models to reduce both bias and variance.
For example, a Random Forest averages predictions from many decision trees, reducing the likelihood of overfitting a single tree while maintaining flexibility. Ensembles are powerful because they balance model complexity and stability, often outperforming individual models.
Understanding how ensembles impact the bias variance tradeoff can guide you in selecting the right modeling approach for your problem.
Monitoring Bias and Variance in Practice
In practice, monitoring bias and variance is an ongoing process. Visual tools like learning curves can help identify underfitting or overfitting.
- High bias: Both training and test errors are high.
- High variance: Training error is low, but test error is high.
Adjusting model complexity, features, or regularization based on these insights helps create a more robust model. Continuous monitoring ensures that your model adapts as data evolves.
Common Mistakes in Managing the Tradeoff
Many beginners struggle with the bias variance tradeoff. Common mistakes include:
- Adding too many features without relevance.
- Ignoring cross-validation results.
- Over-relying on a single metric to measure performance.
Avoiding these pitfalls improves model reliability and trustworthiness. Experimenting with different techniques while keeping simplicity in mind often leads to better results.
FAQs About Bias Variance Tradeoff
Q1: Can bias and variance both be low at the same time?
Yes, but it requires finding an optimal model complexity and sufficient high-quality data. Achieving both low bias and variance is the goal of effective modeling.
Q2: How do I detect overfitting in my model?
Compare training and validation errors. Large differences indicate overfitting, which can be reduced with regularization or more data.
Q3: What is the best way to reduce bias?
Increase model complexity, add relevant features, and consider advanced algorithms like ensembles to capture real patterns.
Q4: How does regularization help with variance?
Regularization penalizes overly complex models, discouraging them from fitting noise and improving generalization.
Q5: Is the bias variance tradeoff the same for all algorithms?
No, different algorithms have different tendencies. Linear models often have higher bias, while decision trees can have higher variance.
Q6: Why is cross-validation important?
It provides an estimate of real-world performance, helping detect both high bias and high variance before deployment.
Conclusion: Mastering the Bias Variance Tradeoff
Understanding the bias variance tradeoff is essential for building reliable, accurate machine learning models. By balancing bias and variance, you can prevent underfitting and overfitting, ensuring your models perform well on real-world data.
Experimenting with model complexity, cross-validation, and ensemble methods are practical ways to achieve this balance. Remember, the goal is not perfection but a robust model that generalizes well. Start applying these insights today to improve your machine learning projects and make smarter, data-driven decisions.




