Introduction
Databases are like giant libraries. Imagine finding a book in a library without an index—it would take ages! Similarly, in databases, searching for data without proper indexing can slow everything down. This is where indexing in DBMS comes in. Indexing is a clever way to speed up queries, reduce search time, and make databases more efficient. In this article, we’ll explore indexing in detail, how it works, its types, advantages, disadvantages, and best practices. By the end, you’ll have a clear understanding of why indexing is crucial in any database management system.
Understanding Indexing in DBMS
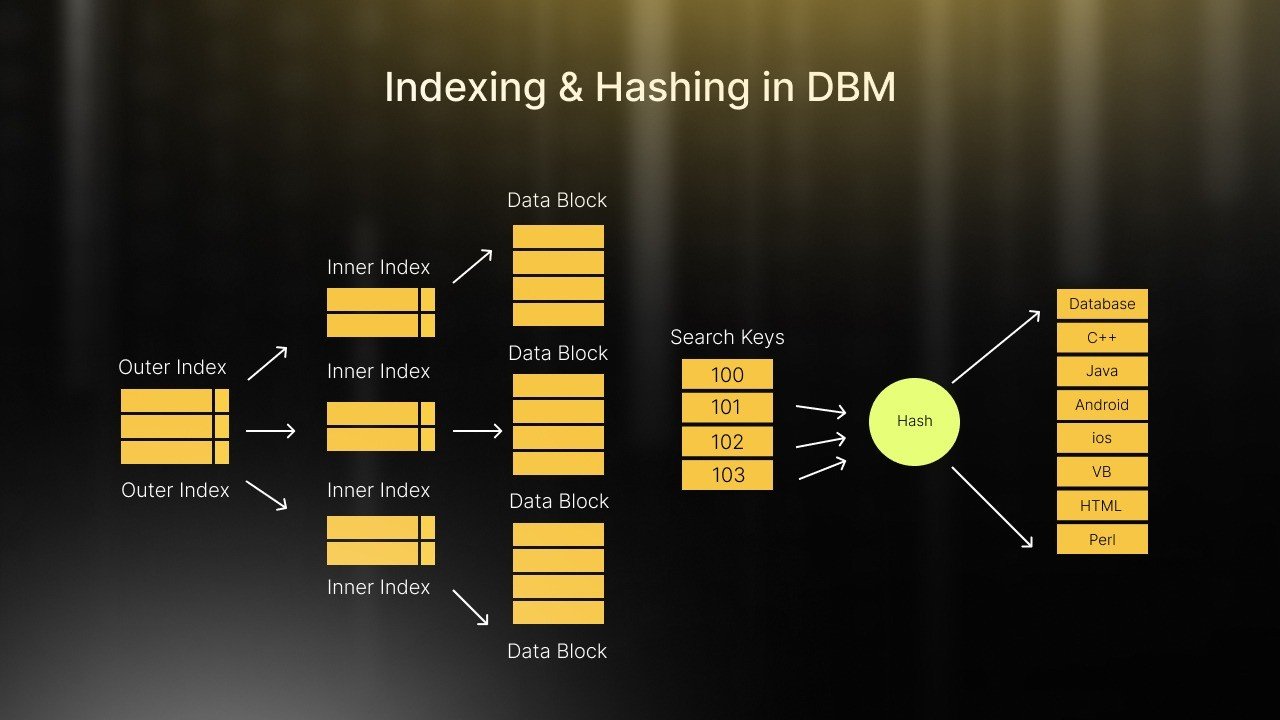
Indexes in DBMS are special data structures that help retrieve data quickly. Think of them as the “table of contents” of a book. Without an index, every time you want something, the database searches the entire table row by row. This is slow, especially with huge tables. By creating an index on certain columns, you can find data much faster. For example, in a student database, an index on the student ID or name allows the system to quickly locate a student without scanning every record. Indexing improves performance but also requires extra storage. So, it’s important to balance speed and storage wisely.
How Indexing Works
Indexing works by creating a separate structure that stores the values of one or more columns in a sorted order. The database can then use this structure to jump directly to the relevant data. There are two main ways an index works:
- Single-Level Indexing: Simple indexes where a single reference points to a record in the table.
- Multi-Level Indexing: Indexes that point to other indexes, improving speed for very large tables.
The database uses algorithms like B-Trees or Hash Tables to organize and search the index efficiently. Essentially, indexing acts like a map guiding the database to the data, cutting down search time drastically.
Types of Indexing in DBMS
There are multiple types of indexing, each suited for different situations:
- Primary Index: Created automatically on primary key columns. It ensures uniqueness and fast retrieval.
- Secondary Index: Built on non-primary key columns to speed up search queries.
- Clustered Index: Rearranges table rows to match the index, improving access time for range queries.
- Non-Clustered Index: Maintains a separate structure that points to table rows without changing their order.
- Unique Index: Ensures that indexed column values are unique.
- Composite Index: Created on multiple columns, helping queries that filter on multiple fields.
Understanding which type to use can drastically improve database performance.
Advantages of Indexing
Indexing provides several benefits:
- Faster Query Performance: Indexes reduce the number of rows scanned.
- Efficient Sorting: Queries that sort data benefit from indexed columns.
- Quick Filtering: Filtering using WHERE clauses becomes faster.
- Improved Join Operations: Indexes speed up joins between multiple tables.
However, while indexes improve read performance, they might slightly slow down write operations like INSERT, UPDATE, and DELETE because the index must be updated too.


Disadvantages of Indexing
Despite its advantages, indexing has a few downsides:
- Storage Overhead: Indexes take extra disk space.
- Slower Updates: Updating indexed columns requires updating the index too.
- Maintenance: Large databases may need regular index maintenance to avoid fragmentation.
It’s crucial to use indexes wisely indexing every column is not practical or efficient.
Indexing Techniques
Some common techniques in DBMS indexing include:
- B-Tree Indexing: Balanced tree structure suitable for range queries.
- Hash Indexing: Uses hash functions for quick lookup, best for equality comparisons.
- Bitmap Indexing: Uses bits to represent data, useful for columns with low cardinality.
Each technique has its use case. For instance, B-Trees are widely used in relational databases like MySQL, Oracle, and PostgreSQL.
Real-Life Example of Indexing
Imagine an online bookstore with thousands of books. If a customer searches for “Python programming,” scanning every book record would take forever. With an index on the book title column, the database can jump directly to relevant books in milliseconds. Similarly, e-commerce websites, banking systems, and social media platforms rely heavily on indexing for real-time performance.
Best Practices for Indexing
To get the most from indexing:
- Index Frequently Queried Columns: Columns in WHERE, ORDER BY, or JOIN clauses benefit most.
- Avoid Excessive Indexing: Too many indexes increase storage and slow writes.
- Use Composite Indexes Wisely: Combine columns used together often.
- Monitor Index Usage: Database tools can show which indexes are used and which are not.
- Rebuild Indexes Regularly: Prevents fragmentation in large databases.
Following these practices ensures high performance without unnecessary overhead.
Common Myths About Indexing
- “Indexes make everything faster.” Not true. Indexes improve reads but may slow writes.
- “All columns should be indexed.” Indexing every column wastes space and reduces write speed.
- “Once created, indexes are permanent.” Indexes may need regular maintenance or dropping if unused.
Understanding these myths helps database administrators make better decisions.
Future of Indexing
Modern databases are evolving with adaptive indexing and automatic index tuning. Tools like Oracle’s Automatic Indexing or SQL Server’s Intelligent Query Processing reduce manual work by analyzing query patterns and creating/removing indexes automatically. This trend shows that indexing is not static but continues to adapt to big data and real-time applications.
Frequently Asked Questions (FAQs)
1. What is indexing in DBMS?
Indexing is creating a data structure to speed up data retrieval from a database table.
2. How does indexing improve performance?
Indexes allow the database to locate data directly rather than scanning the entire table.
3. What is the difference between clustered and non-clustered indexes?
Clustered indexes sort the actual table rows; non-clustered indexes maintain a separate reference.
4. Can indexing slow down a database?
Yes, excessive indexing can slow write operations and increase storage needs.
5. Which indexing technique is best for large databases?
B-Tree indexing is commonly used for large relational databases due to its balanced structure.
6. How to choose which columns to index?
Columns frequently used in WHERE, JOIN, and ORDER BY clauses are ideal candidates.
Conclusion
Indexing in DBMS is essential for fast, efficient, and reliable database operations. It’s like giving your database a superpower to find data in milliseconds instead of minutes. However, proper planning, maintenance, and strategy are crucial to avoid pitfalls. By understanding types, techniques, advantages, and best practices, you can design databases that are both powerful and responsive. Start small, monitor performance, and expand indexing wisely to make the most of your database system.




